Distributed object storage overview (Study notes)
Block File and Object storage
Block storage: raw blocks attached to a server as a volume. mutable, higher cost and higher performance, however lower scalability casue it could only attached to one server and good for VMs and databases.
File storage: built on top of block storage, higher level of abstraction, handle files and directories, medium to high performance and cost, medium scalability, which provides general purpose file system access, good for sharing files/folders within organization.
Object storage: sacrifice performance for higher durability and vast scalability with low cost. it is generally immutable however version is supported. it targets relatively colder data, access is through Restful apis.
Requirement for object storage
This blog is more about object storage. It provides Restful Apis, includes PUT, GET object.
Business entities: bucket(folder) and object.
High level components
High level we have web server, index component and storage component:
For get object, the request first reaches web server, query metadata from index component and use the result to get back data from storage.
For put object, the request first reaches web server, then call storage component to select a place to store data, put the data there, then save the mapping into index component.
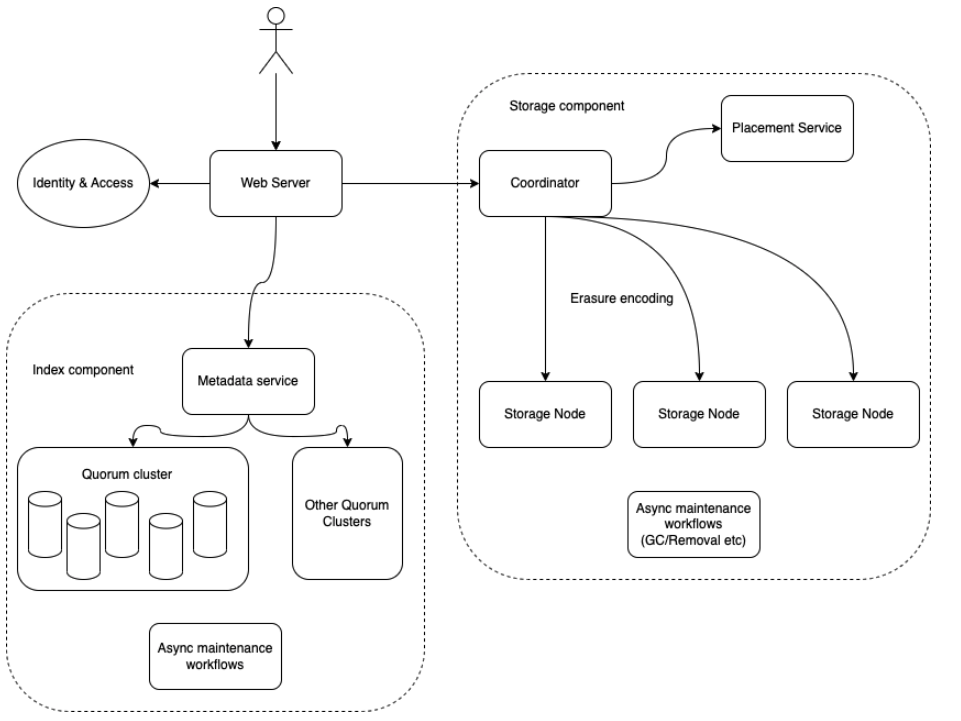
Web server responsibilities
A stateless service, its responsibilities include:
- Request throttle: to rate limit requests, includes early stage throttle, i.e. 1200 concurrent connections in total, per customer throttle. etc
- Authentication: verify caller is valid.
- Authorization: after querying metadata, verify caller has permissions of specific buckets/objects.
- Request processing: calling dependency services and process requests.
- Metering: emit metering logs for charging customers.
- Logging: emit audit logs.
Index component
Index is a key value type of metadata store that maps user key names (e.g. bucket: foo, object: myPuppy.jpg) to actual object locations in storage component, it primarily contains object metadata information like where the storage is stored, ACL, tag information, storage class etc. Index layer entries tend to be small and mutable upon customer updates.
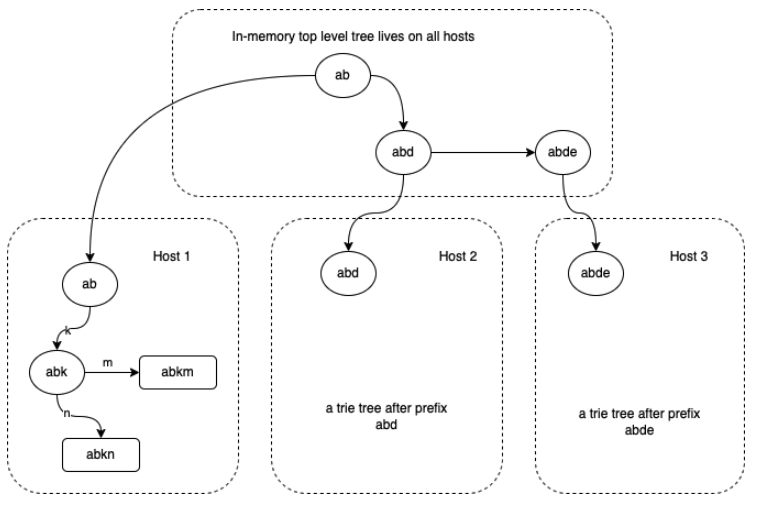
Trie tree
Typically, large scale data storage applications, like relational databases, store their data using trees - often B-trees. But there’s another option for storing sorted data - trie tree. B trees have simpler properties than tries, more “even” performance due to it is more balanced.
But in replication, trie based data structures can be more efficient for keeping replicas synchronized.
Anti-entropy Merkle tree
Merkle tree is a binary tree of hashes, where each internal node is the hash of its two children, and each leaf node is a hash of a portion of the original data.
Since distributed system replies on replicas, and a protocol is needed to compare diffs and converges data between replicas.
Merkle trees is suitable for anti-entropy process, since it can minimize the amount of data that needs to be compared and transfered.
By combining trie tree and merkle tree, it allows quick insertions, lookups and range queries, and merkle tree is mainly about fingerprint of all data that shares a particular prefix, which is important to replication and anti-entropy. this could not be done efficiently using a B Tree structure.
Stratified tree
This prefix trie tree could be growing large, and hard to fit in memory or a single host’s disk, stratified tree is a way to go.
A stratified tree is a regular tree broken up into connected pieces, with each piece stored on a disk block.
A estimation is that the tree entries takes something like 64 bytes on average, assuming some reasonable set of entries. So if we have between 1-10 million entries, that takes up 64MB to 640MB. so memory will constain us to single digit million entries on a node.
Less than twice tree leaf entries (conservative estimation), so assume we need 64 bytes per tree entries. In addition, we need to store the actual data of the leaf entries. Say there’s 36 bytes of data per block. Then we need 100 bytes per entry in total. So if we have a hundred GB disk, we can store one billion tree entries.
So we should be able to manage a one billion entry trie tree on a reasonable host.
Quorum
Why need quorum?
when data is replicated across multiple nodes, we need a way to declare read/write success. This allows system to be able tolerate a certain number of node failures, also it maintains consistency and availability.
Quorum is hard to find during a network partition and when hit host is in the minority group. also since for each read/write, it needs multiple hosts to response, which introduces some latency.
How?
Assume that:
1 | N = total nodes |
Then Quorum is defined as
1 | W + R > N |
for example:(N=3, W=1, R=3): fast write, slow read, durability is bad due to single copy.(N=3, W=3, R=1): slow write, fast read, durability is good. servers can be unavailable so availability is not good.
For read heavy system, this is better: 1 < R < W < N
Majority-Based Quorum: R = W = (N/2)+1 for example: (N=5, W=3, R=3)
Storage component
Durability is the key for storage layer, under no circumstance we would want to lose customers’ data. durability is achieved by replication data on multiple disks.
The durability number depends on several different factors:
- (1) failure rate
- (2) amount of time it takes to detect a disk failure and repopulate data on another disk (mean time to repair).
Trade-off for higher durability is cost, more copies comes with higher cost. we can use replication count factor as a measurement for cost.
How to choose best durability type?
Questions to ask:
(1) how big is the storage data?
(2) read frequently or infrequently (hot or cold)
(3) require multi-AZ availability / can tolerate high read latency
(4) durability
(5) cost
Hard drives
It is vital to plan according to manufacturer and real-world benchmarks to maximize your storage performance. Take a look at peak IOPS and throughput ratings, read/write ratios, RAID penalties, and physical latency, etc.
IOPS: input/output operations per second, calculated by: 1 second / (Average Seek Time + Average Latency)
IOSP for SSD: 3000 to 40000 while for HDD, it is around 55-180.
Throughput for SSD: up to 2000 MBps, HDD maybe couple hundreds MBps.
SSD: solid state drive, HDD: hard disk drive
Anecdotal data
- HDD: Seek time: 4-9 msec
- SSD: Seek time: 0.08-0.16 msec
Durability - Erasure coding
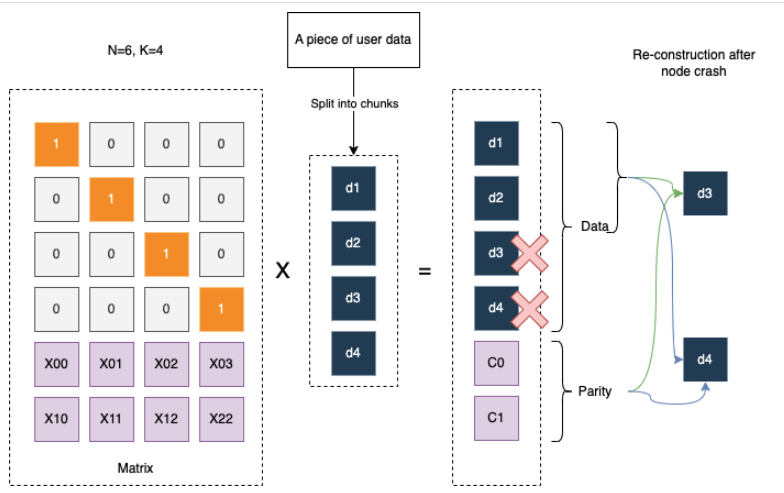
Erasure coding: use the magic of math (Galois fields and Reed Solomon encodings), we can split the object blob into smaller shards, and erasure code them such that we can reconstruct the blob with a subset of the shards.
We then store different shards on disk. Let’s call the total number of shards N, and the required number of shards K, the replication count used to estimate cost would be N/K.
1 | PUT path: Matrix[NxK] x Data[Kx1] = Physical Shards[Nx1] (K of them is data, N-K is parity) |
Smaller K might be optimized for small and hot objects. while for large and cold blobs, need to optimize for small replication count factor for lower cost.
Erasure coding is trading read/write performance (more IOPS, CPU calculation, Network) for lower cost and higher durability.
Below is an example of Reed-Solomon encoding with four data units and two parity units:
Data integrity - checksum
We normally guarantee data integrity by calculating a checksum and store it with data.
To calculate a checksum, a cryptographic hash function like MD5, SHA-1, SHA-256, or SHA-512 is used. The hash function takes the input data and produces checksum, and store checksum together with data. when client retriving data, it uses checksum to verify the received data is not corrupted. otherwise it should retrieve data from another replica.
Anecdotal data
| Checksum algorithm | Compute time(64KB) |
|---|---|
| SHA256 | 35 microseconds |
| MD5 | 24 microseconds |
| SHA1 | 19 microseconds |
| CRC32 | 1.1 microseconds |
| CRC32C | 1.0 microseconds |
Garbage collecction - compaction
Async and lazy deletion, its responsibilities:
- (1) merge storage blobs into continuous blobs.
- (2) delete unused storages.
we should measure burn rate (rate of creation minus rate of deletion) and ensures that there is enough available space for another X days.
Discovery: Gossip Protocol
Each node keeps track of state information about other nodes in the group and gossip this information to one other random node every second. This way, eventually, each node gets to know about the state of every other node in the group.
This is a peer-to-peer communication mechanism in which nodes periodically exchange state information about themselves and about other nodes they know about.
Compare with DNS, it is not centralized and compare with static configuration, it is more scalable.
The drawback of gossip protocol is it could be hard to forget some information in the gossip network.
Multipart upload
There are 3 main steps:
(1) Initiate multipart upload
this will call an API and get an upload Id
(2) Concurrently upload parts with upload id
Parts are stored in a special partition “parts/”
Parts key – bucketId#key#uploadId#partNumber
After each part finished uploading, it will return a eTag.
(3) Complete multipart upload
Pass in a list of part numbers and eTags, which is used to assemble multipart object
Server will return success or not.
