Tradeoffs when growing a large scale distributed system
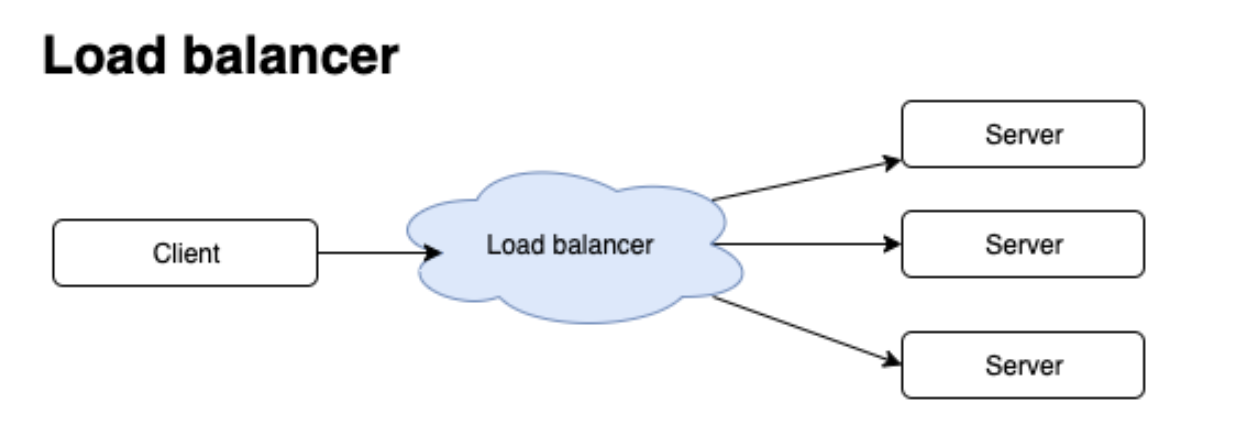
A simple load balancer
To start with a very simple point, clients connect to your service through network, a load balancer routing requests to different fleets.
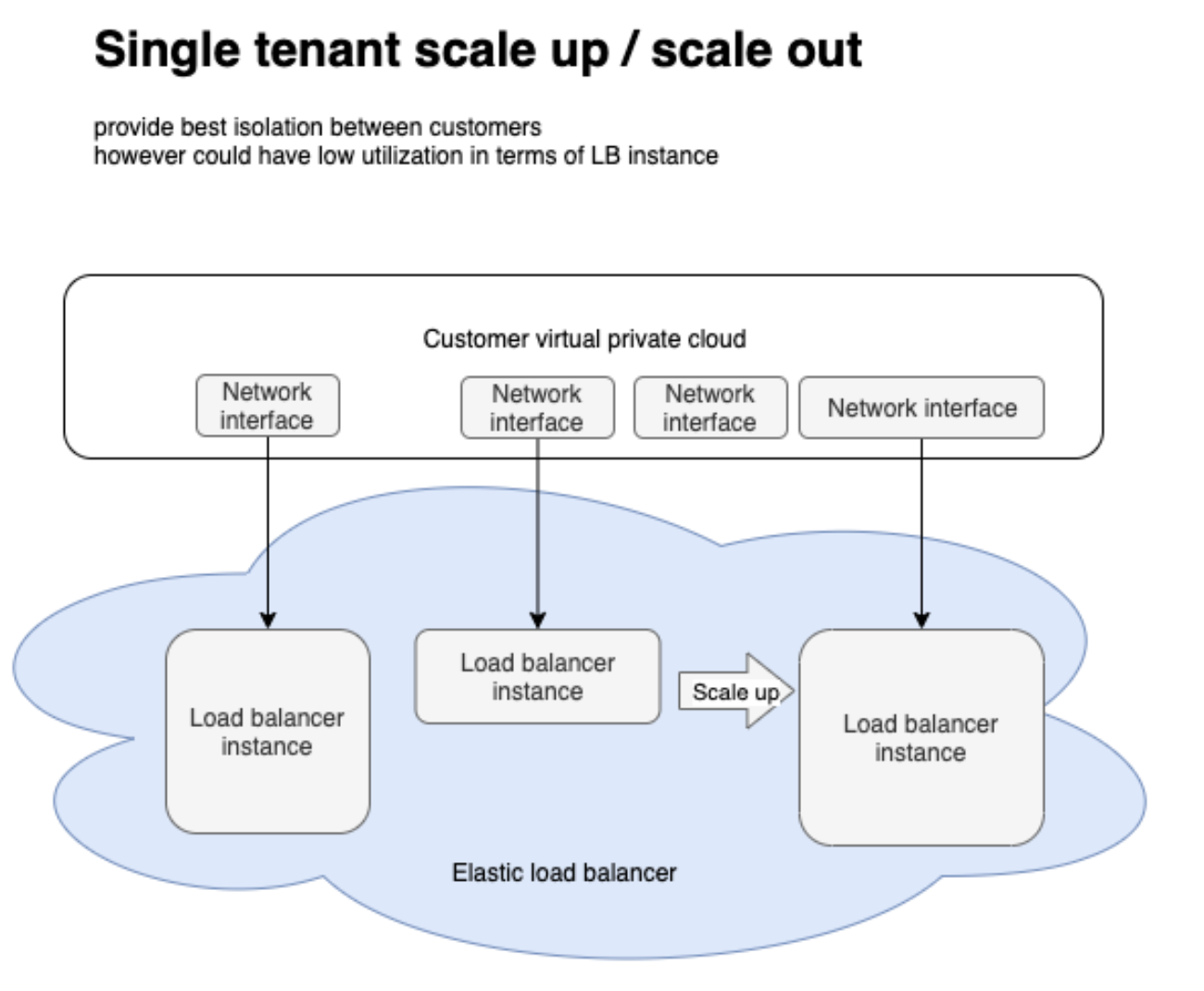
Single tenant LB
Starting from a single tenant load balancer, what that means is for every customer which has load balancer, there is a ENI created in their VPC and cross attached to the server in service provider’s network. normally there will be another standby instance for redundancy.
In this case, customers can send various type of traffic to our LB, which means we need to scale up/out our capacity, which could be done vertically by adding large instance type or horizontally by adding more instances.
This created churns for customers since every time we scale up or out, we need to update DNS and customers could cache DNS, staffs like that.
The drawbacks are: it just cannot keep scaling, utilization might be low, deployments take time.
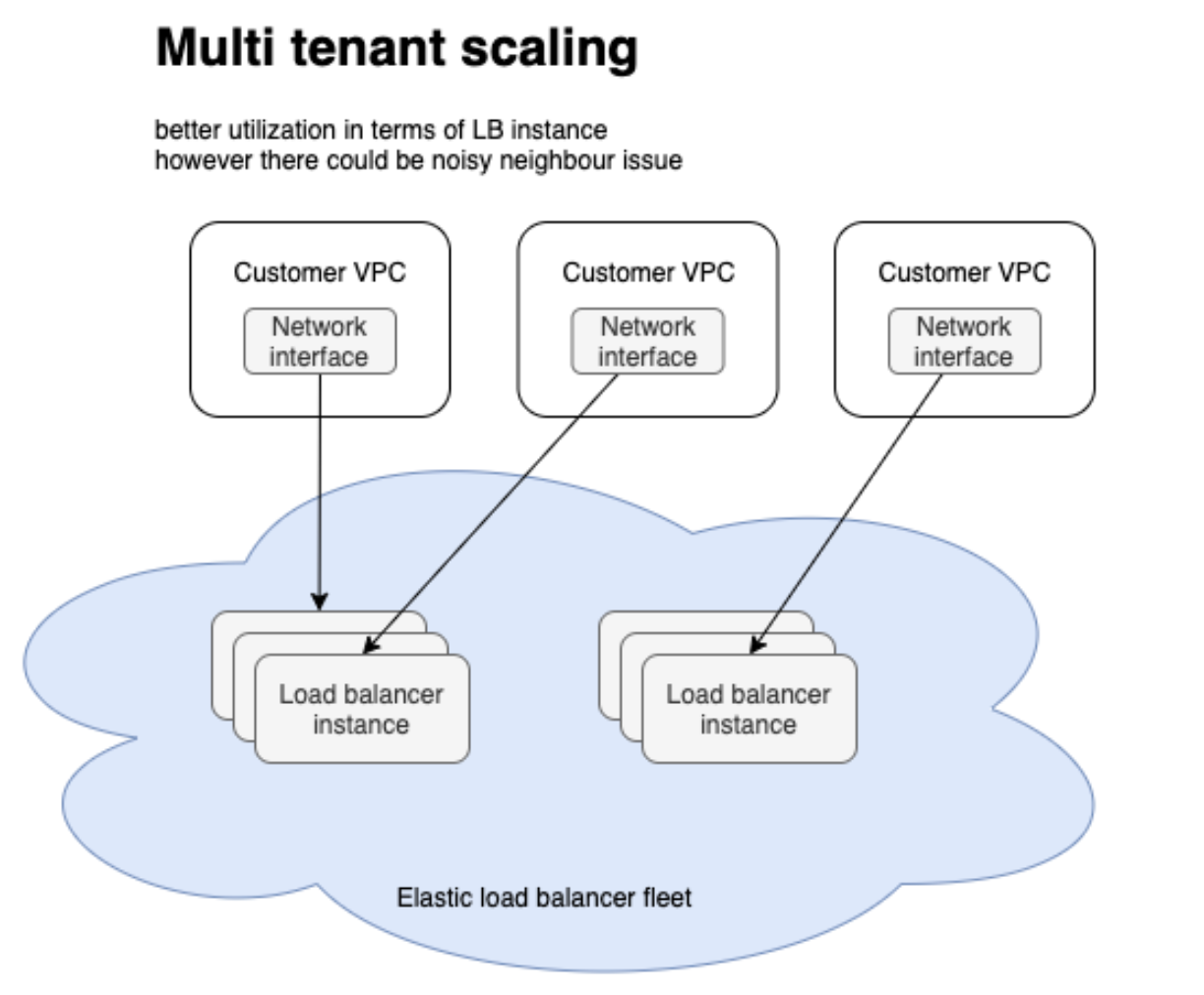
Multi tenant LB
Compare with single tenant system, multi tenant system provides better utilization, faster deployments(more agile) also larger buffer capacity to absord traffic, since it is shared by a set of customers.
What is the trade-off?
Noisy neighbors issue: a single customer is having a bad day cause impact to other customers
Even with sharding technology, it would still impact customers on the same shard.
While for single tenant system, it has best isolation, and smallest blast radius.
To solve isolation issue: shuffle sharding
As below graph, when customer B has a bad day, they will likely bring down instance 1,3,6 while other instances remain intact. customer A, C, D still could be mapped to a good instance.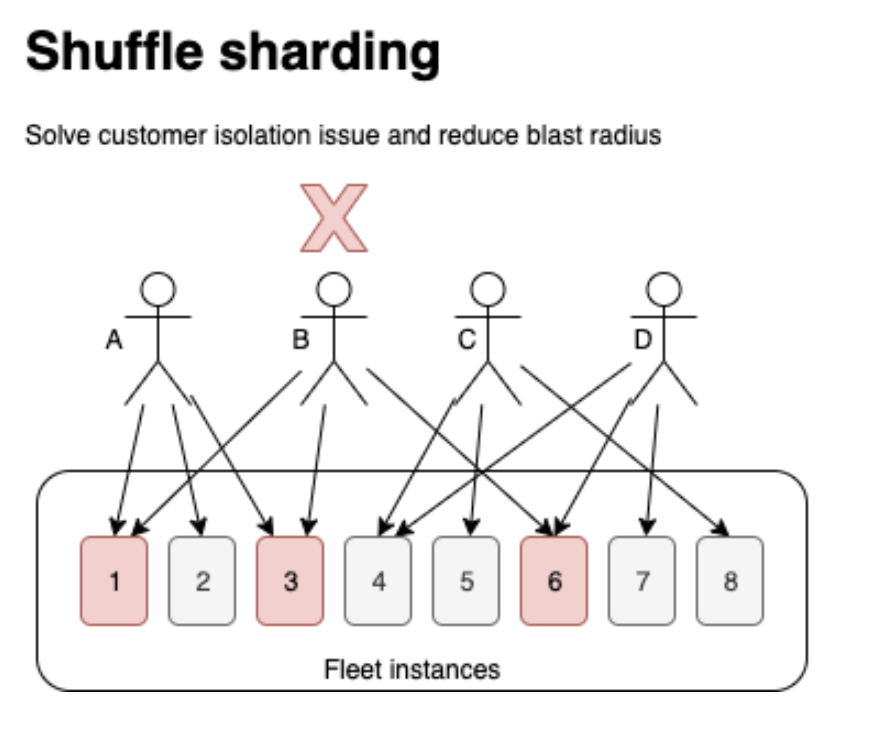
Possibility of overlap could be decided by below 3 factors:
- number of nodes/number of instances
- number of shards
- number of customers
This would be a trade-off between isolation VS capacity.
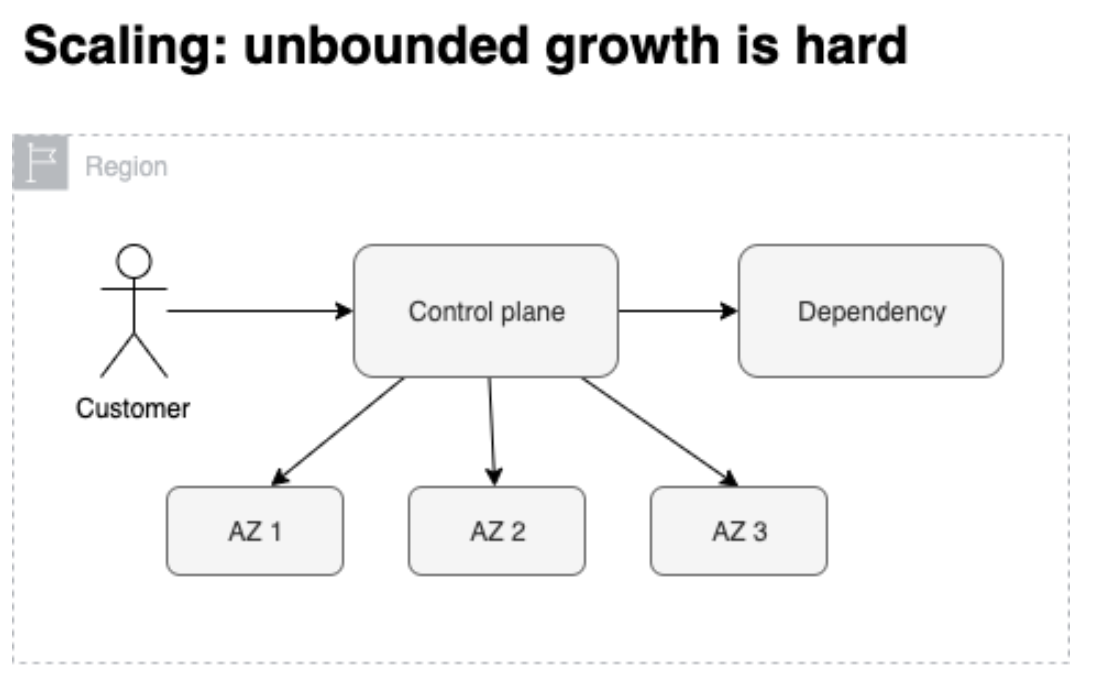
Scaling: unbounded growth is hard
Even data plane is more distributed, but we still have only single control plane that governs each region.
For big region, it is impossible to test. other than that, this becomes an edge case to our dependencies, and which could hit dependency system’s unknown scaling limit.
Best practice: don’t be an outlier / big pain to dependency, since we don’t know when it will hit dependency’s limit.
Cells are the answer
Within a single cell, both control plane and data plane scaling limit would be bounded in this case, so we know we are approaching failure.
Each instance has some buffered capacity for new customers.
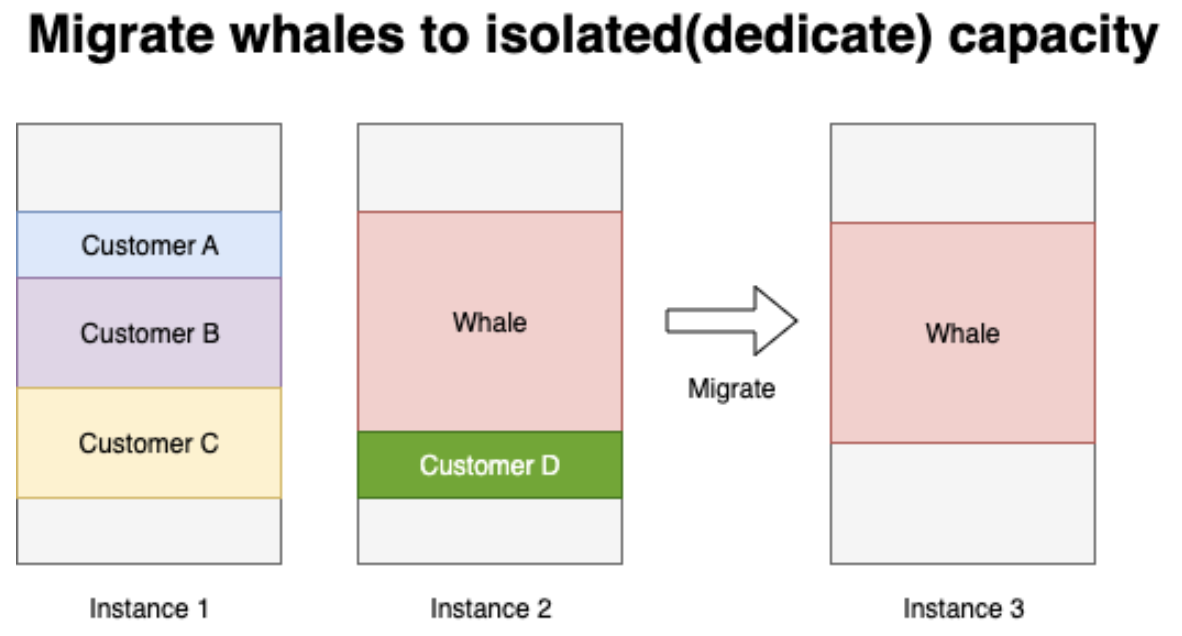
Then in this case, whales become a big problem. whales are customers either have large config or high traffic, it could fall into any extreme case.
We have no way to know a whale when creation, there is no indicators.
When whales appears, they could soaked up lots of buffered capacity so quickly that cell is approach to its limit.
In this case, we could automatically migrate whales to isolated capacity to protect other customers.
This is a trade-off between complexity VS flexibility.
Cell architecture is complex however it provides some flexibility when growing.
preset cell size
Using flexible cell size will be more friendly to cost, while costy to test.
By having multiple cell sizes, it will reduce the overall cost and increase the complexity to test, a trade-off between cost VS testability.
data plane scaling factors
Likely the scaling event of data plane will be:
- new connections per second
- active connections
- bandwidth.
By having fewer instances, we will save some cost however will increase blast radius of event and have poorer isolation.
This is a trade-off between cost VS blast radius.
